
Physical AI Has a Massive Data Problem
Every major wave in AI has produced a breakout data infrastructure company. Text gave us Scale AI. Code and knowledge work gave us Mercor. Both are now valued north of $10 billion.
As we enter the era of Physical AI - foundation models that control robots, humanoids, and embodied agents - the question isn't whether a data company will emerge.
It's who will build it, and what it takes to win.
We've spent the last several months going deep on this space, talking to researchers across leading robotics labs and startups.
This is our thesis on why data collection for Physical AI is a massive, time-bound opportunity - and what the winning company might look like.
There Is No Internet for Robots
When OpenAI trained GPT-3, the raw material was already sitting there. Trillions of tokens of text accumulated over decades of human activity on the internet. Physical AI has no such luxury. The models that will power humanoids need to learn from first-person video of hands interacting with objects - ideally with depth, force feedback, and the texture and friction of real materials.
Today, that data sits at roughly 0.1% to 1% of what LLM training required to reach frontier capability. The field needs 100x to 1,000x more - and that gap is the central bottleneck in Physical AI today.
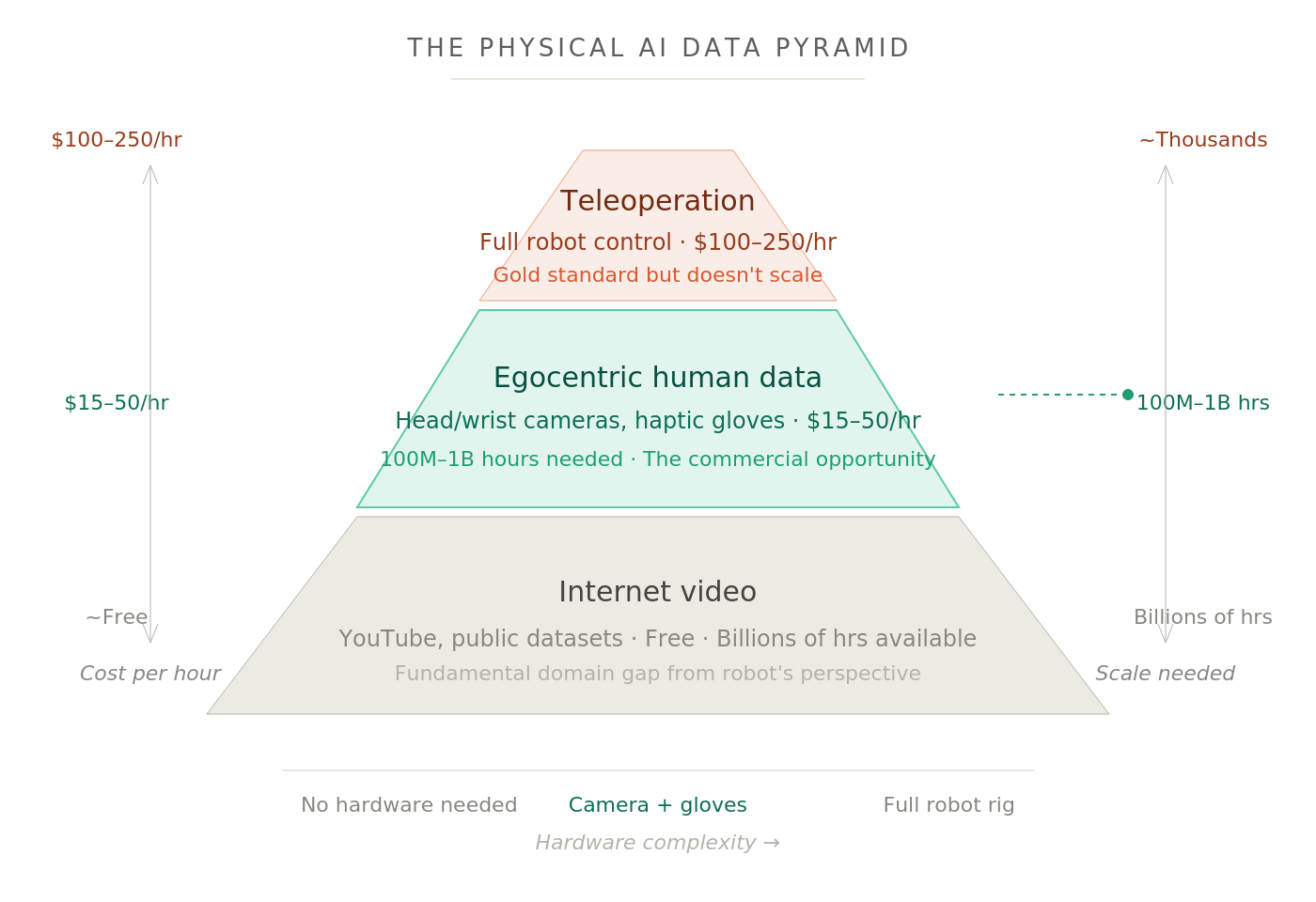
The Data Pyramid
Physical AI has converged on a training paradigm borrowed from LLMs: pre-train on vast, diverse data, then fine-tune on task-specific demonstrations. The data that feeds this process looks like a pyramid.
At the base sits internet video - YouTube clips, activity recognition datasets, and similar public footage. It's abundant and free. But third-person video has a fundamental domain gap from a robot's egocentric perspective, and scraping YouTube isn't a viable path to physical intelligence.
The next tier - and the one we find most interesting - is egocentric human data. Cameras worn on someone's head or wrists with haptic gloves, recording a first-person view of everyday tasks. It captures human hand motions, object interactions, and environmental context in a format that translates far more naturally to robot learning. This is the closest thing to "internet-scale" data that Physical AI can get. It needs minimal hardware and can be collected by non-specialists in almost any setting.
At the top is teleoperation data - a human physically controlling a robot. This is the gold standard: exact motor commands, force profiles, contact dynamics in the format that models need for deployment. It costs upwards of $100 per hour and is brutally hard to scale. A researcher at one of the labs told us their goal is to reduce teleoperation dependency from 30-40% of training data to just 5-10%, with egocentric data filling the gap.
The pyramid also maps onto a hardware axis. Internet video needs nothing. Egocentric needs almost nothing (a camera on your head). Intermediate approaches use gloves and haptic sensors. Teleop demands the full robot rig. The most interesting commercial gap sits between the tiers: approaches that push fidelity up without a massive proportional jump in cost.
Why Egocentric Data Works
The key insight is that diversity matters more than precision at the pre-training stage. The market will reward companies that can deliver massive volume across diverse environments, tasks, and object categories - not those obsessing over laboratory-grade quality at small scale.
The economics are striking.
Leading robotics labs converge on a need for 100 million to 1 billion hours of egocentric pre-training data over the next two to three years. At $15-50 per hour - raw unlabeled footage at the low end, fully annotated high-fidelity data at the top - that implies $1.5 billion to $50 billion in cumulative data spend.
Purchasing is campaign-based: a lab buys hundreds of thousands of hours ahead of a training run, evaluates the resulting model, then decides what to buy next. But the aggregate demand is enormous and accelerating.
How to build defensibility
The biggest risk here is commoditization.
The barriers to getting started are low: cameras are cheap, people are available, basic logistics aren't complicated. Supply already exceeds demand by one to two orders of magnitude. Many vendors rushed in once robotics funding surged. DoorDash has partnered directly with a robotics company for egocentric data collection, cutting out intermediaries entirely.
Quick-service companies in India are entering the market to monetize their existing workforces.
The gap between entering the market and operating at scale is where natural selection happens. And the survivors will be very hard to displace.
What It Takes to Win
Get embedded in the lab's training pipeline.
Every leading robotics lab has specific requirements around hardware, collection protocols, and data formats.
The winning vendor operates more like an embedded partner than a standalone data supplier, iterating on hardware and protocols in tight feedback loops with customers.
Build global supply.
A single-geography vendor - even one with significant cost advantages - faces a ceiling. Labs want 100,000 hours from ten geographies, not a million hours from one. The environments in which robots will operate - American kitchens, European factories, Asian retail stores - are different enough that data from a single country cannot provide the diversity pre-training requires.
The winning company needs operations across multiple geographies, with collection happening in homes, factories, retail spaces, hospitals, and construction sites.
Control the collection hardware.
Not all egocentric data is created equal. The market is segmenting between cheap phone-captured footage (useful but limited) and purpose-built collection rigs with calibrated cameras, stereo depth, haptic gloves, and wrist-mounted sensors. Annotation requirements include natural language labels every 5-10 seconds, human-defined segment boundaries for atomic motions, and overall video summaries - adding roughly 20% to collection cost.
Companies that maintain quality at scale while keeping annotation costs manageable will command premium pricing.
Build toward post-training.
Pre-training data is the land grab, but the higher-margin, stickier business is in post-training: teleoperation setups, specific collection environments matched to deployment contexts, and the tooling to manage increasingly complex data pipelines.
Companies that build this capability alongside pre-training collection will capture more of the value chain and be much harder to cut out.
Execute reliably.
Managing a large, distributed workforce collecting physical data across multiple countries is genuinely hard and operational excellency will be the biggest determinant of growth.
Is it a transitionary business
Egocentric data collection has a shelf life. Once humanoids deploy at scale, every task they perform feeds back into training. That flywheel eventually reduces the need for human-collected demonstrations.
Our view is that this transition is 5-7 years away from meaningfully displacing demand. The flywheel needs deployed robots at scale. And the data has to come from somewhere before enough autonomous robots are out in the world to generate it on their own.
The better framing is that the data problem changes shape. Someone has to manage, curate, and optimize the data that deployed robots produce. RLHF didn't kill data companies in the LLM world. It created new categories of data work. We expect the same in Physical AI.
India as a beach head geography
India is the natural starting point.
For pre-training data - where diversity of motion and task coverage matters more than geographic specificity - India offers a massive, cost-advantaged workforce for collection and annotation, a growing ecosystem of manufacturing and service environments, and millions of workers already performing the domestic and industrial tasks that models need to learn. Data collection can be layered on top of existing labor rather than built from zero.
Geographic specificity only begins to matter at the fine-tuning stage, and even for deployment-specific data, the differences between Indian and other-country home environments are bridgeable with relatively small amounts of targeted collection.
But India can't be the whole story. The winner goes global from India, not just deep within it.
The Window is Closing
Labs are signing exclusive data licenses. Vendor relationships are hardening.
The 30-50 companies operating in this space today will compress to 5-10 within the next 3 years. The entry period won't last forever.
Sometimes tailwinds alone create large outcomes. The volume requirements here are genuinely staggering, the window is narrow, and the infrastructure doesn't exist yet. We think this is one of the defining data bets from India of the next decade.
We're actively looking for founders building in this space. If you're one of them, we'd love to chat. Reach out at sayantan@stellarisvp.com

.png)
.png)
