

If AI in 2015 was a promise for most enterprises, it’s already a storm across all of enterprise software in 2021. Across software, hardware & services, AI makes up a $300B+ global market today, which is poised to cross $500B in all likelihood by 2024.
R&D in AI has continued to explode: no. of AI researchers on arXiv has been growing at 50%+ YoY for 15 consecutive years now. Yet, companies are struggling with getting nice ideas from data scientists’ Jupyter Notebooks to work in production – 80% AI projects never make it to deployment. Although a startling fact to digest, it starts making intuitive sense once one begins to appreciate how hard it really is to deploy an ML model in an enterprise-grade production environment.
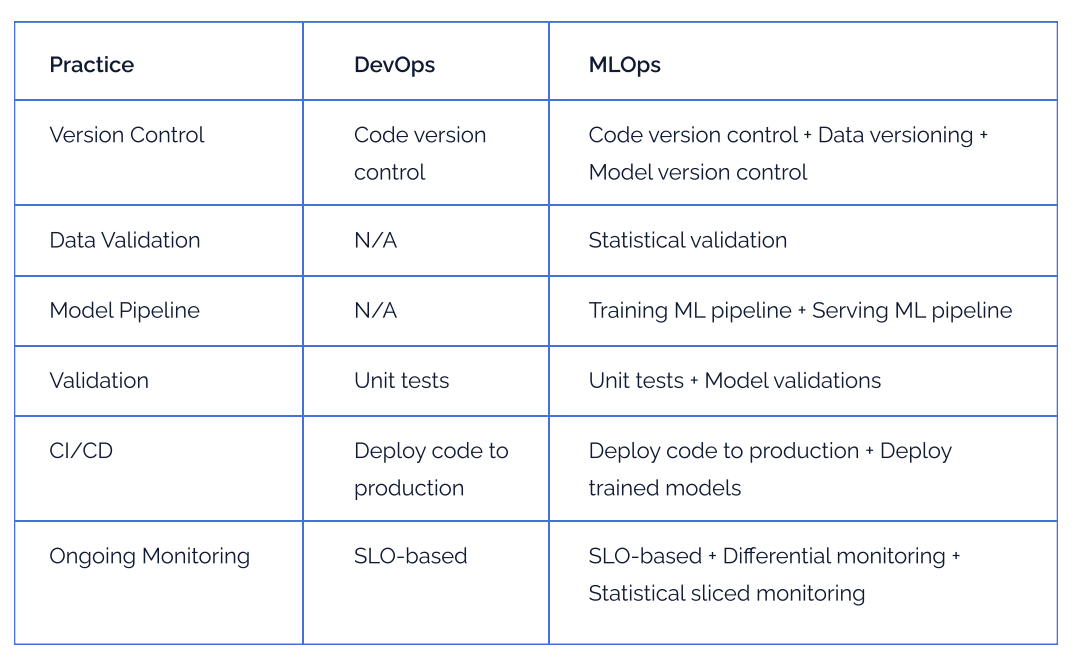
AI-software is fundamentally harder than “regular” software to build & deploy, because an AI system is not just composed of code: it’s code + ML models + data, with all three intricately entwined. Therefore, while the advent of DevOps has led to adoption of scalable ways to collaborate-on & release software at cloud-velocity, an entirely new set of practices & systems are needed to do the same for AI-software.
Enter MLOps.
In terms of complexity, MLOps considerably encompasses DevOps, necessitating the need to develop new tooling and hence, justifying the emergence of a standalone software category.
As AI adoption accelerates & enterprises scramble to scale their internal MLOps, several opportunities have opened up for new tools & platforms serving the unique needs of data science teams. In fact, MLOps is the fastest growing category within all of AI-related software.
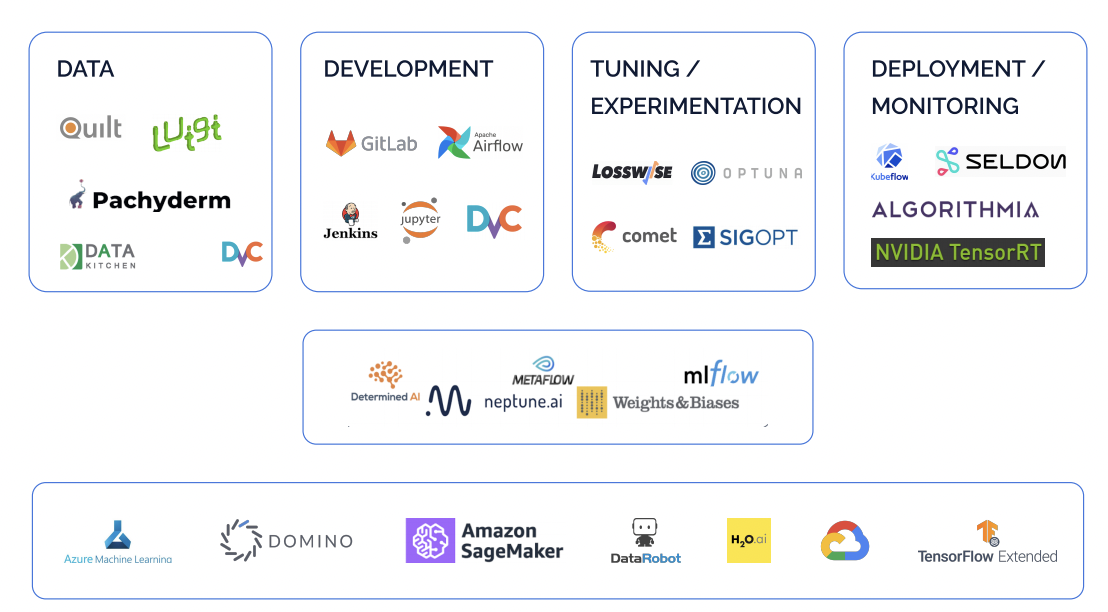
There are 200+ MLOps platforms today, with some vying to differentiate as a specialized “best-of-breed” solution (Neptune for experimentation, Kubeflow for deployment), & others promising a complete “best-of-suite” platform (AWS Sagemaker, DataRobot).
At Stellaris, while we are tracking the entire evolving landscape of MLOps closely, we are particularly excited about the following opportunities:
1. Deployment platforms: A typical data scientist might enjoy fine-tuning hyperparameters in a neural network, but they are most likely not an expert at managing CI/CD pipelines or spinning up Kubernetes clusters. Add to it the ever increasing complexity of enterprise infrastructure due to the rise of hybrid-cloud & multi-cloud environments, and infrastructure provisioning & management starts becoming intractable for most, if not all, data scientists.
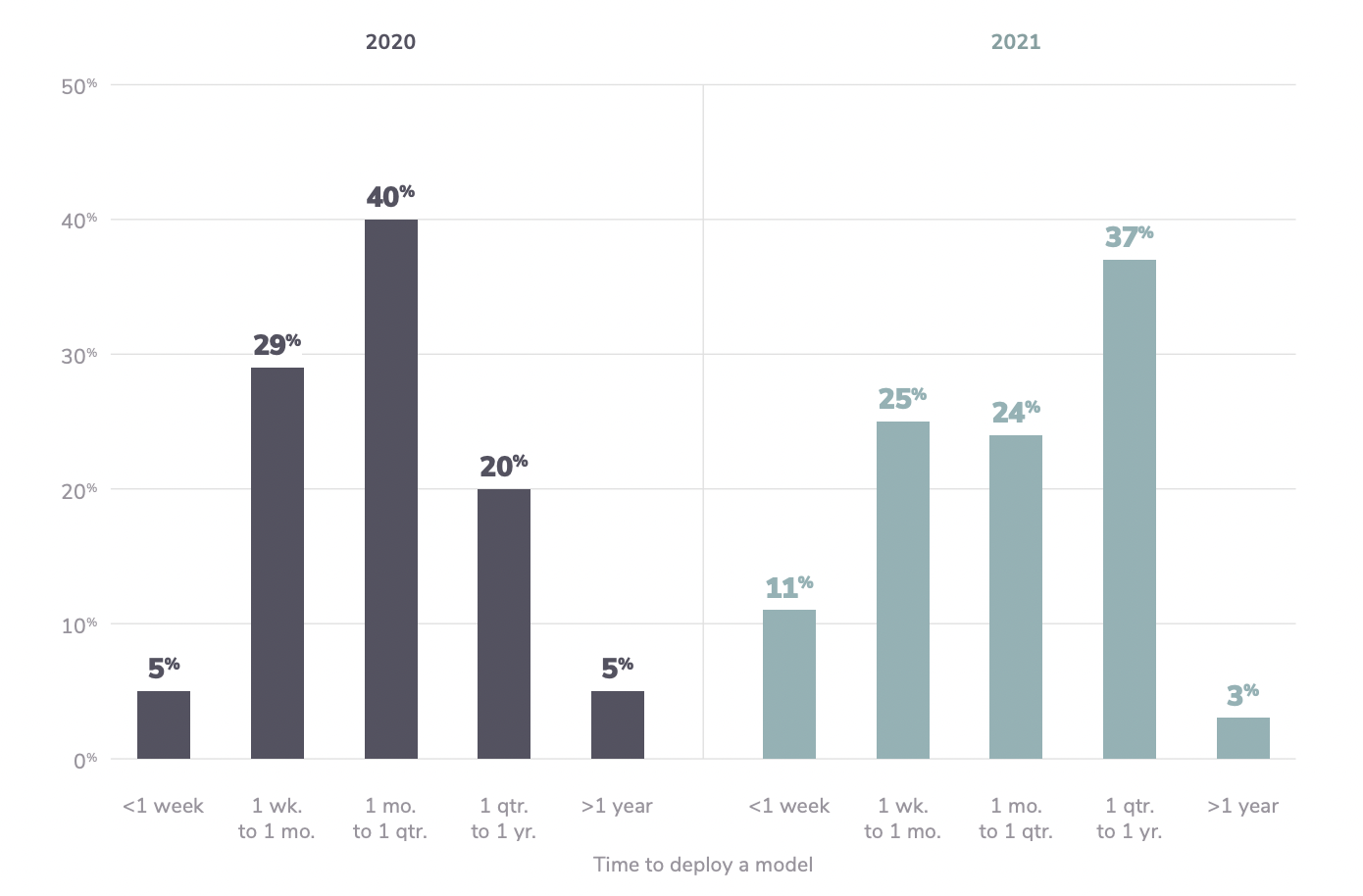
Src: Algorithmia- 2021 enterprise trends in machine learning
They thus most likely need to rely on a separate IT team to deploy their models – a messy process bound to be marred by losses in translation, backtracks, & versioning issues. In fact, around two-thirds of organizations confess to taking more than a month in deploying a trained model in production. Furthermore, deployment is only getting lengthier: 2021 saw longer avg times for model deployment than 2020. There exists a massive current opportunity for platforms that abstract away the nitty-gritties of deployment pipeline management & infra provisioning – ie, letting data scientists focus on data science. Recent developments at companies like DataRobot, Kubeflow, Coiled, etc point to model deployment platforms being a hot & competitive space for startup opportunities in the near future.
2. Feature Stores: Much of ML-engineering is centred around leveraging the right set of “features” (relevant direct or derived data points) from swathes of raw data. Increasingly more data science teams are realizing the importance of efficiently extracting, transforming, & serving features. A well designed feature store architecture (example below) not only handles all of the above, but also makes it dramatically more convenient to maintain data lineage, enhance explainability, & monitor model performance in production – all worthy goals in ML.
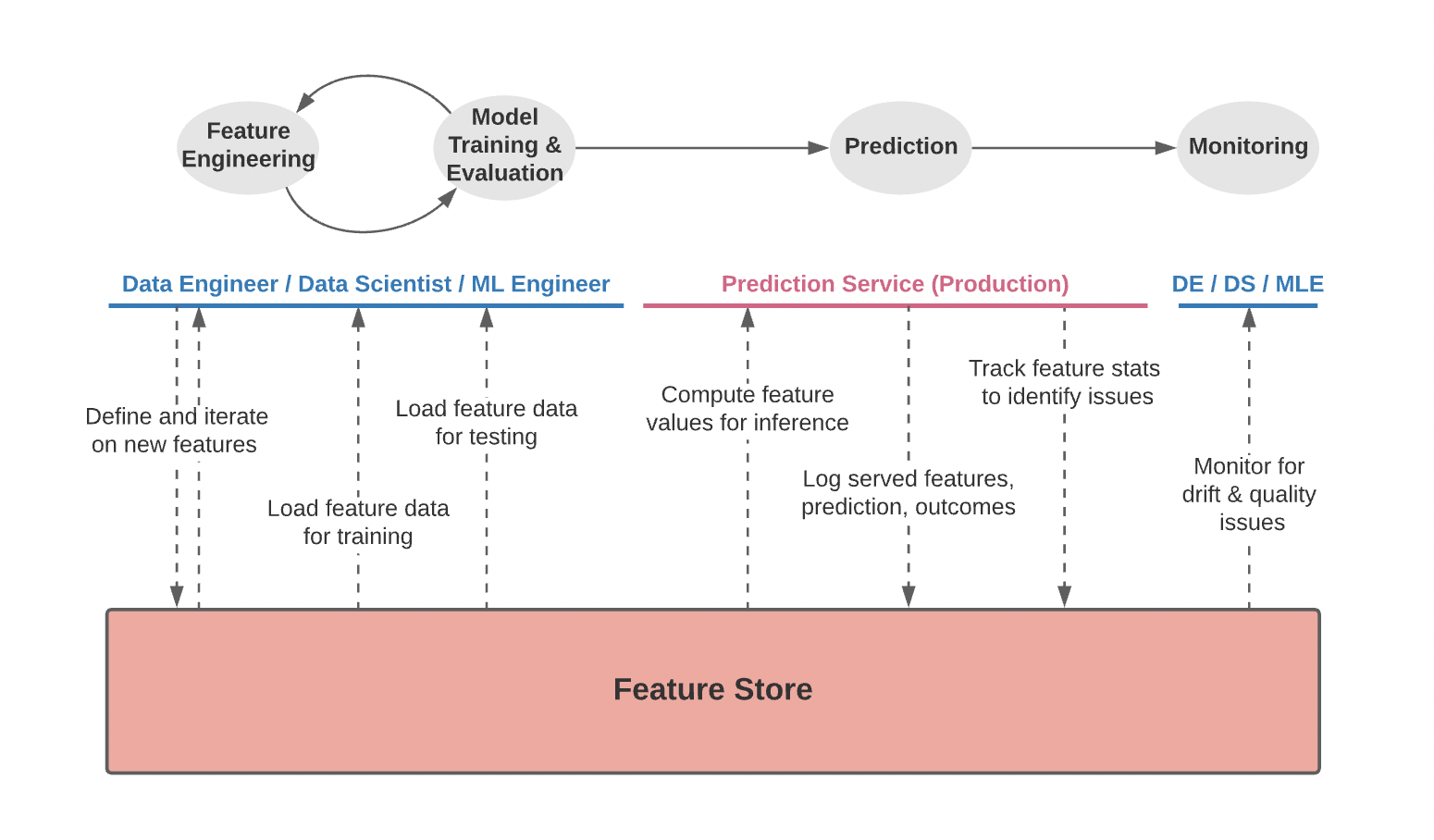
Src: Tecton ai: What is a feature store?
Justification for using feature stores can be derived from the fact that some of the most successful ML teams in the Silicon Valley (Google, Uber, Netflix etc) have been using some forms of internal feature stores for years now, without necessarily using the terminology. Tecton AI, founded by the team that helmed Uber’s celebrated Michaelangelo ML platform, is fast emerging to be an early thought leader in the space. 2021 might even be the year when feature stores go mainstream – with AWS & Databricks announcing their own offerings & multiple open-source platforms gaining steam (Feast, Hopsworks).
3. API-fied Experimentation Platforms: Unlike regular software wherein the output of a module in development is expected to be deterministic, ML models are statistical entities fluctuating rapidly in performance & behavior with changes in model architectures & parameters. A compelling majority of a data scientist’s model building time involves experimenting with existing pre-trained/untrained models and building customized model pipelines on top of them. Platforms like Google’s Vertex AI & H20.ai let data scientists rapidly iterate through, & track model experiments. 25% of large organizations were already selling and/or buying data via formal data marketplaces in 2020, and we see similar “model marketplaces” emerging & growing ubiquitous over time to cover the long tail of ever-exploding ML models (eg, HuggingFace for NLP) .
We will see more platforms that allow rapid prototyping & iterations in model building, with both trained & untrained models available as easy to integrate building blocks – akin to the “APIfication” of development over the last 5 years (Twilio, Stripe et al).
4. ML Observability: Data science teams can spend months on building the perfect model & see encouraging initial results, but they can be in for rude surprises as their models are deployed in production and start ageing. Firstly, there can be a gap between training & production performance – either driven by inconsistency in feature transformation pipelines or simply because production data happens to have a different statistical distribution from training data. Secondly, in almost all real-world scenarios, data isn’t static like a piece of code, but actually almost a “living” entity that can change distribution over time (read data & concept drift). That means models that were working like a charm in the first few weeks post deployment need to be retrained/fine-tuned with new data to remain relevant.
Add to it the complexity of convoluted data pipelines & non-deterministic nature of most of today’s sophisticated ML algorithms, and tracking model performance plus executing root-cause analysis becomes a tough MLOps problem needing specialized solutions. Companies like Arize, Fiddler, Censius & Superwise are interesting early movers in the space but ML Observability is still very much a large market ripe for the taking.
At Stellaris, we find MLOPs to be one of the most tumultuous (& thus, exciting) spaces in SaaS today, akin to the ~2008 environment around DevOps, when it had truly started emerging as a separate category. If you are building in this space or generally have thoughts to share on the article, we’d love to hear from you at anagh@stellarisvp.com!