

Sometime in 2017, we had the opportunity to speak with Deepak Anchala, co-founder and CEO of Slintel. Deepak was building a SaaS company in the sales intelligence space. It was early days for him. We shot some breeze and exchanged ideas on where within the sales funnel he could focus but did not think much of it – at that point, it seemed the space was already taken. We reconnected in 2018 and then again in 2019. Slintel had more narrowly defined its focus by that time – Slintel allows B2B marketers to discover high potential prospects for their business based on deep inferences on their intent. Deepak was kind enough to let us be a partner in his journey right at the ground level in mid-2019.
Since the investment, we are fortunate to have had a ringside view of building Slintel. While we knew the secret sauce of what Slintel offers is not “functionality”, but the underlying “data”, it is only by working more closely with them that we are figuring out how different it is to build a Data-as-a-Service (DaaS) company, compared to Software-as-a-Service (SaaS). There are lots of similarities too, but it is important to recognize that SaaS and DaaS is not a like for like comparison.
Even though it has only been a little more than a year, here are some early learnings:
- MVP takes longer to build: It is hard to pre-guess which customer will look for what data or insight. Therefore, you need a minimum coverage to be able to provide value to customers. In Slintel’s case, they started by targeting the HR/ recruiting space, i.e. companies that are taking an HR/ recruiting product or service to market. It is a horizontal offering, and hence any company can be a target. As such, Slintel collected data on 17M businesses (with data being gathered and analyzed every week), across thousands of parameters. Slintel also realized that for SMBs in particular, this data was of little use unless there is people and contact information for target companies. Building this massive data engine was not easy!
- Don’t over engineer or under-engineer accuracy: This is one of the toughest choices for entrepreneurs to make. How much accuracy do you need in your data? Like with most things in life, getting to 70-80% accuracy happens very rapidly. Going from 80 to 90% might take the same effort as the first 80%. Going from 90 to 92% may take more effort than everything combined so far. So where do you draw the line? A simplified way to think about it is a 2×2 matrix of patience and risk threshold.
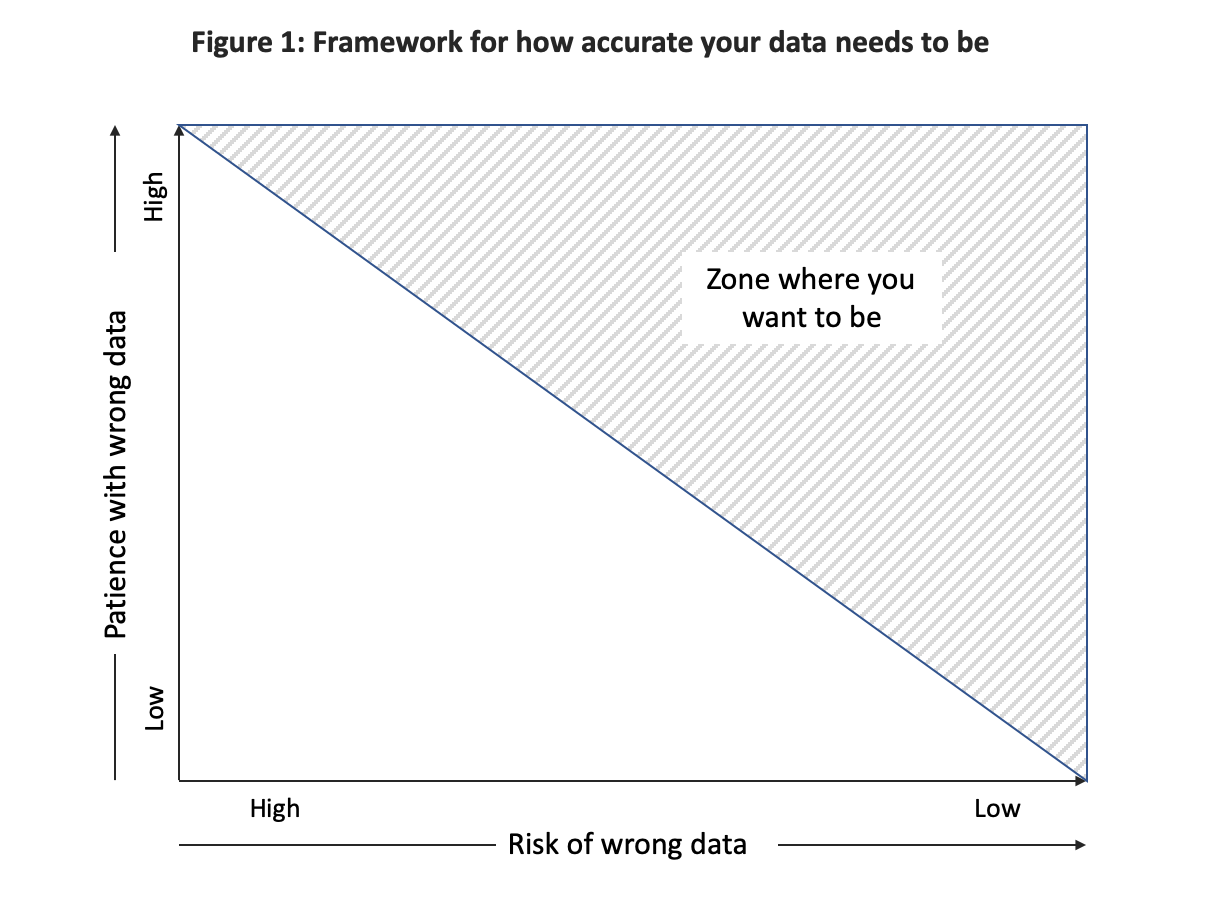
There is no one size fits all answer. If you are using a data service to underwrite insurance cover for an expensive property, your data better be very accurate. On the other hand, while scoring a lead, 800 vs 900 employees for a prospect is unlikely to make much difference. That is risk. At the same time, even if the risk is not very high, annoyance level can be high if 50% of the data is wrong.
Each use case has its own threshold for fault tolerance. An entrepreneur’s deep understanding of the target customers will matter the most in “right sizing” the accuracy of data.
- The best sales tools need no education: Sales intelligence data has been in use for at least the last 3 decades. Hoovers, D&B and many others have been built on that premise. Users know if they have better data on their prospects, they can prioritize them better, and also personalize the messaging. B2C marketers have taken this to art from through technology. In B2B, this has been more brute force. It is not for a lack of need, but more for a lack of good alternatives. Slintel is lucky to be in a position where their product needs no education on the need – prospects actively search for it. Furthermore, it needs no implementation, and customers can pilot it within a week. This has helped them scale fast. It’s hard to build the product with the right volume and quality of data, but relatively easier to go to market once you have the right product.
- Moat comes from proprietary data or workflow integration: Flip side of the above argument is that this product category can lead to high churn if there are better alternatives. Building a moat, therefore, is not easy. Much like Slintel has replaced existing solutions, it can also be replaced by others in future. Moat can come from three different sources:
- Proprietary data: There are many DaaS companies that aggregate data from multiple sources and provide access to customers through one common channel. Yes, it has some value, but in today’s age of APIs and their discoverability, very little. This value proposition is very easily replicable and therefore not defensible. However, access to proprietary data can create a moat. Zillow in the US is an example of proprietary data where homeowners provide their own data, and Zillow also complements it from other places. Network effects of the business ensure that it is not easy for someone else to replicate.
- Hard to replicate inferences: In the absence of proprietary data, one needs to be able to generate insights from the data that are not easy to replicate. For example, the knowledge that a new VP of HR has joined 3 months back and used Workday in their last job can be combined with new job postings for a Workday administrator on the company’s web site to infer with a high probability that the company either already has or will soon be going live with Workday. While this example is trivial, one can imagine that hundreds of data points, if combined intelligently, can help one make pretty smart conclusions that were not obvious.
- Deep integration into user workflows: Given the pace at which data and its sources are growing, it will be increasingly hard to differentiate just with proprietary data or inference. In the long run, such products should not just be a source of data, but need to be deeply embedded into the workflow. We have experienced that first hand in another portfolio company – Signzy – which provides 250+ third party data APIs, but they also control the customer onboarding workflow for financial services institutions, and therefore become very hard to displace.
- Need for a high scalability tech platform: Data collection can and will grow exponentially. Before you realize, you will be collecting so much data that your underlying architecture will begin to show fissures. Slintel is collecting and analyzing 100B data points every week. In every board call, we discover more data that is being collected and new patterns that are being looked for. The underlying architecture needs to be solved for sooner rather than later, before you realize that the “data flood” is breaking the banks of your technology stack.
- Being patient with gross margins: During our early board meetings, we compared Slintel gross margins against early stage SaaS. Early stage Indian SaaS companies can often have very high GMs – 85-90% – even though they come down a bit as scaling happens. DaaS is just the reverse. Given point #1, data collection and augmentation involves a lot of costs early on (and so does the underlying infrastructure), therefore leading to lower GMs. However, these improve significantly over time as the company scales. Be prepared to invest in the right data early on, and be patient with the GMs.
Like any start-up journey, many lessons learnt will turn out to be either wrong or not applicable beyond a certain point, and there will be new lessons along the way. But that wealth of learning is precisely the reason one builds companies. We are looking forward to learning more as Slintel scales, and inshallah, creates a defining DaaS company from India that is emulated by many more in the years to come.